Patent claim dependencies and LLMs

It's been a while since my last post - lots of things are happening in parallel. Besides my day-to-day work, I'm currently building an international patent online community - a place where professionals and anyone interested in patents can meet, share ideas, and chat. On top of that, I'm working on a side project called pto-sync.com, which makes it easier to automate workflows based on patent and trademark office actions - whether for custom docketing tools or double-docket setups.
But I don't want to stop sharing knowledge about the patent tech world. Since I've been working with large language models (LLMs) in this context, today's topic combines both worlds: patent claim dependencies and how LLMs can help analyze them.
What are patent claims?
At the core of every patent are its claims. They define the scope of what's actually protected - or, more precisely, what the patent holder has the right to forbid others from doing commercially within the jurisdiction of the patent. In simple terms, the claims are the legal boundaries of the invention.
There are two main types:
- Independent claims – stand on their own, not referring to any other claim.
- Dependent claims – refer to one or more other claims in the patent.
This distinction is crucial.
When checking for patent infringement, also known as freedom to operate (FTO), the focus is on independent claims. If your product or process covers every single element of an independent claim in an active patent within the jurisdiction where you operate, you should definitely talk to a professional.
This doesn't mean dependent claims can be ignored. They come into play later - but starting with independent claims makes sense, both for efficiency and risk assessment.
When drafting a patent, inventors and attorneys usually want the broadest protection possible, so they write the independent claims as wide as possible.
Patent examiners, however, often push back, arguing the scope is too broad. That's where dependent claims come in. They provide fallback positions. If necessary, elements from a dependent claim can be moved into the independent claim so the patent gets granted.
This means the granted patent may look different from the original application.
Dependent claims also help clarify the scope of the independent claim and serve as backup during litigation.
For example, if someone challenges a patent by proving the independent claim was already publicly known, the patent owner can "narrow" it by pulling in details from dependent claims to keep protection alive.
So while independent claims are the starting point, dependent claims definitely matter.
Patents can have many claims. In some jurisdictions, only one independent claim per patent is allowed. In others - like the US - you can have multiple independent claims. And sometimes, the most important claim isn't the first one.
So the bottom line is this: always know which claims are independent.
How can you spot dependent vs. independent claims?
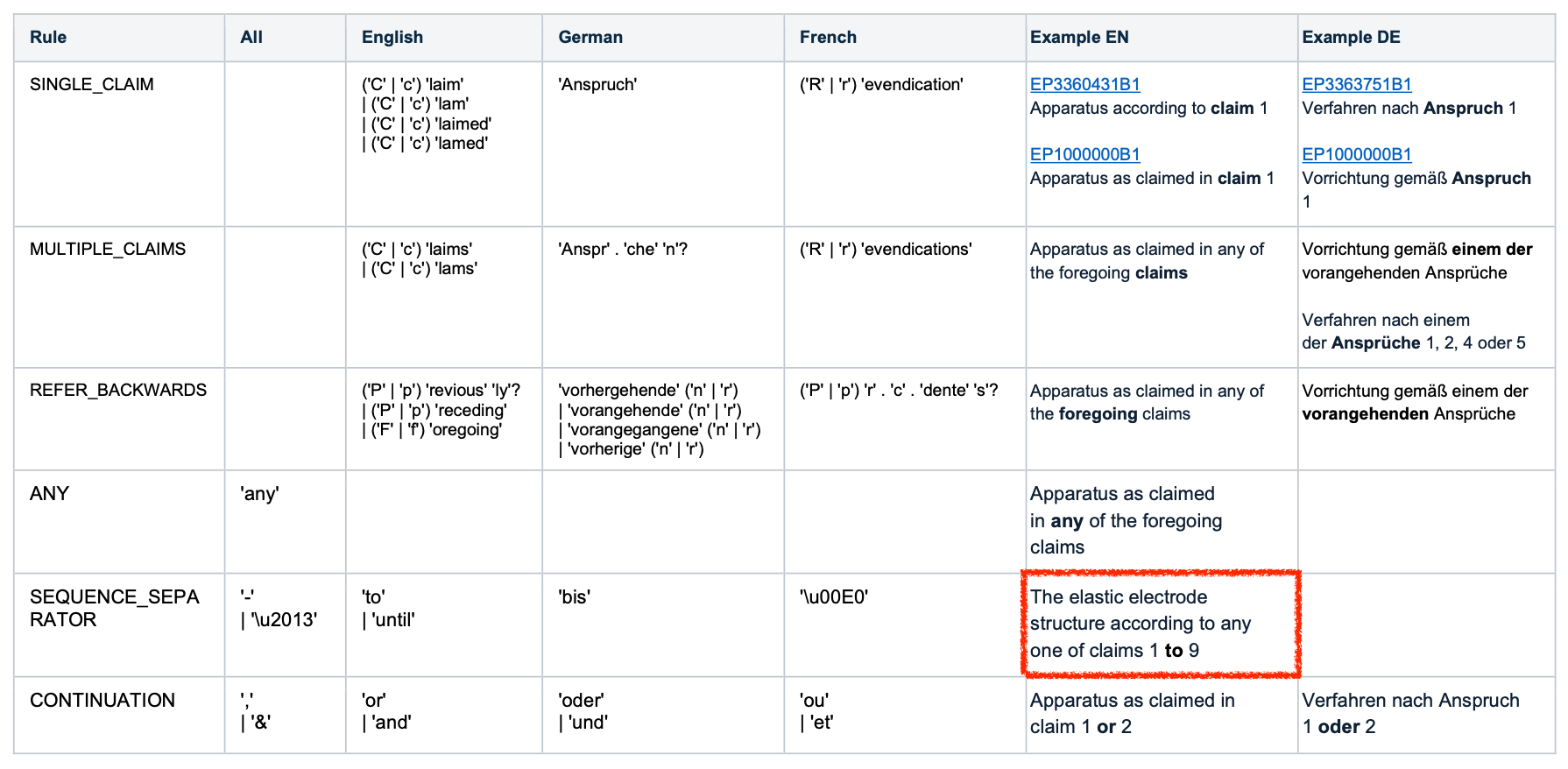
You can either read the claims yourself - if you see wording like "according to claim X" (or similar), it's dependent - or you can let software do it for you.
Many professional patent tools include automatic claim dependency analysis. But these tools aren't perfect, for several reasons:
- Poor OCR quality can cause errors.
- Algorithms may not support all languages.
- Sometimes wording like "the preceding claims" isn't correctly handled.
There's also research on this specific topic, for example Patent Claim Structure Recognition (2017)
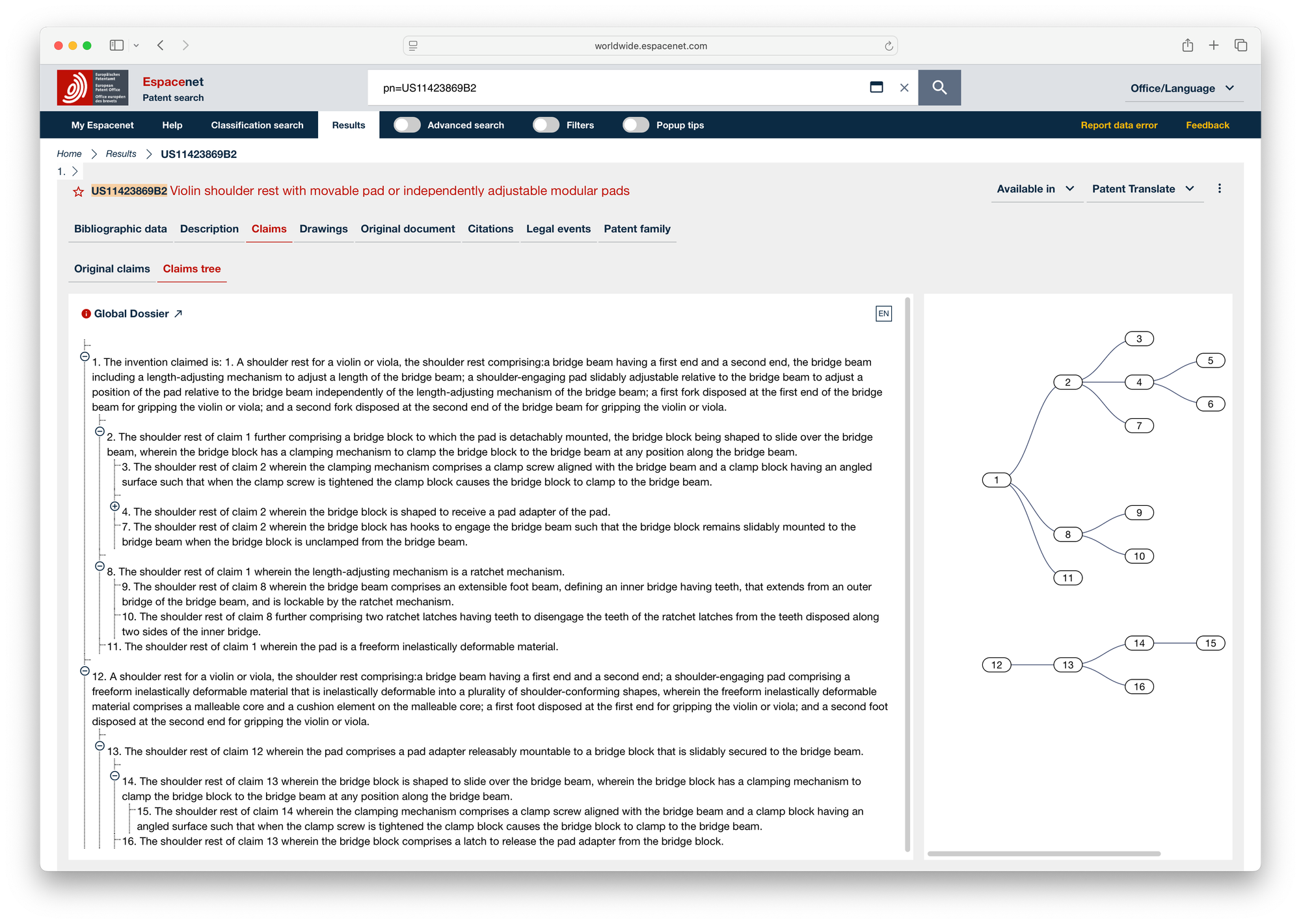
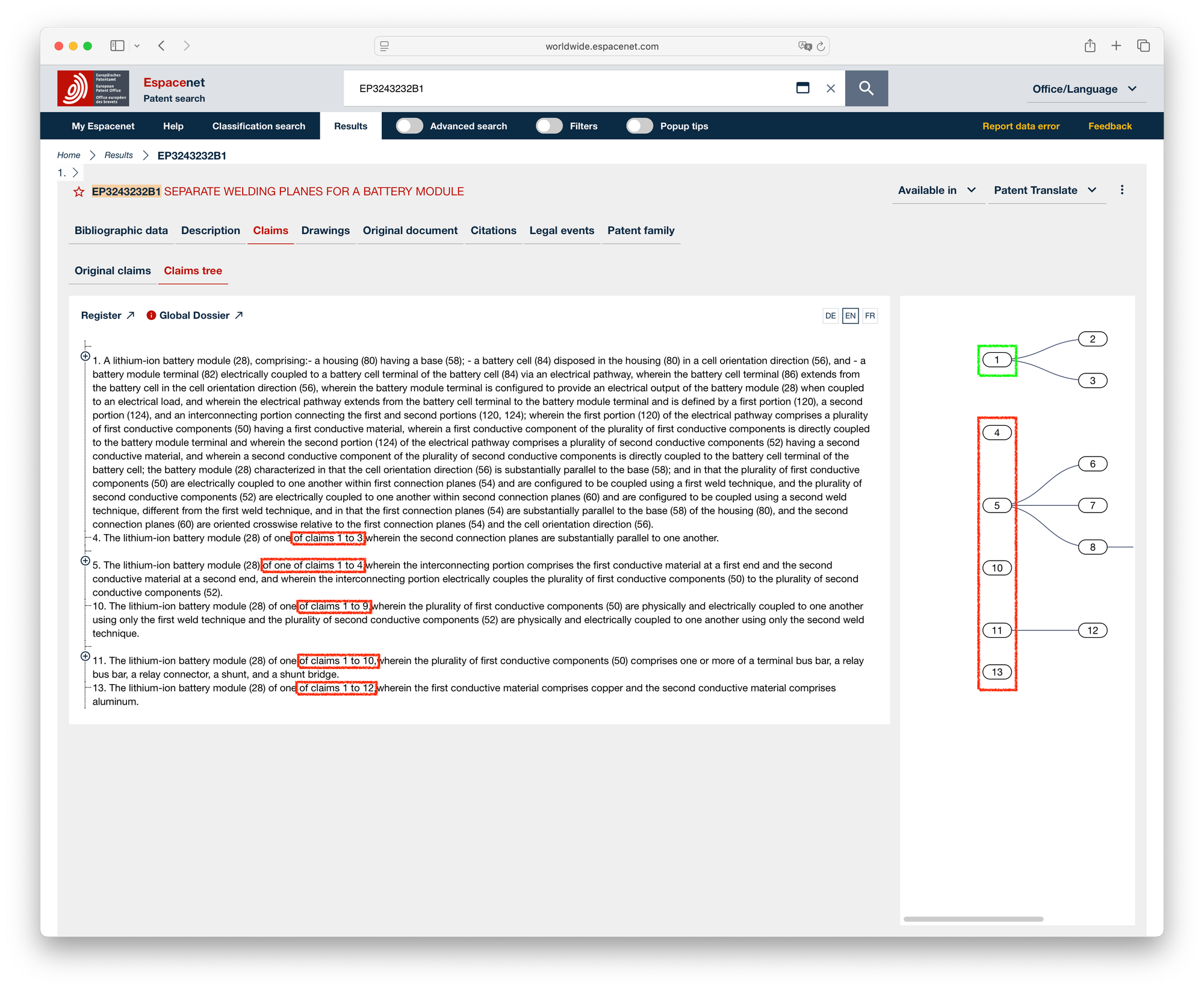
Recently, I ran into this issue again while working. I was curious whether there were new solutions available, so I contacted EPO. The excellent patent data team at the EPO shared this link with me. Interestingly, while Espacenet uses this logic for its claim dependency tree view, the EPO doesn't provide it via OPS or in their bulk data products.

After work, I decided to experiment with local large language models (LLMs) - small ones, running on just 4 GB of memory.
The results? Surprisingly good. In less than an hour, I had a Dockerized web service up and running that provided a JSON API to detect claim dependencies. It used Ollama and Qwen2.5-Coder:7B, and after some fine tuning, all of my test assertions were met. Interestingly, the small model did not perform worse than the OpenAI API. And I hadn't even started training a model.
The wrong dependencies of EPO, could be determined correctly with this approach:
Prepared claims for AI analysis documentNumber=EP3243232B1 claimCount=13 Analyzed claim number=1 independent=true referencedClaims= Analyzed claim number=2 independent=false referencedClaims=1 Analyzed claim number=3 independent=false referencedClaims=1,2 Analyzed claim number=4 independent=false referencedClaims=1,2,3 Analyzed claim number=5 independent=false referencedClaims=1,2,3,4 Analyzed claim number=6 independent=false referencedClaims=5 Analyzed claim number=7 independent=false referencedClaims=5,6 Analyzed claim number=8 independent=false referencedClaims=5,6,7 Analyzed claim number=9 independent=false referencedClaims=8 Analyzed claim number=10 independent=false referencedClaims=1,2,3,4,5,6,7,8,9 Analyzed claim number=11 independent=false referencedClaims=1,2,3,4,5,6,7,8,9,10 Analyzed claim number=12 independent=false referencedClaims=11 Analyzed claim number=13 independent=false referencedClaims=1,2,3,4,5,6,7,8,9,10,11,12
The LLM approach is particularly useful when dealing with machine translations. It's impossible to hard-code every possible wording. For example, an English translation of a Korean patent might say "according to paragraph 1" or "according to article 1" instead of "according to claim 1". LLMs handle these variations far better.
But of course, LLMs can generate non-deterministic responses and hallucinations. A hybrid approach with smart confidence handling can achieve more robust results on lower quality input as major platforms like Espacenet currently provide.
Working with LLMs in patent data feels like having won the golden ticket to Willy Wonka's factory. There are so many things to explore and try out.
It's genuinely fun!