Current state of patent text data
No single database contains all patent texts. Formats differ between authorities, API access typically requires payment, and OCR introduces errors. This guide explains the challenges of accessing patent text data and what it would take to create a truly open, global resource.


Key takeaways
- No single database contains all patent texts. Patents are national rights managed by individual authorities.
- Not all patent text is digitized. Jurisdictions prioritize recent documents over historical ones.
- Data formats differ between authorities. You need to handle various formats when working with patent text from different sources.
- Historical patents were scanned as images. OCR is required to make them searchable, but OCR can introduce errors.
- There are both free and commercial providers of patent text. API and bulk data access from authorities typically require payment, though EPO recently made some products free.
- Licensing restrictions control redistribution. Authorities may provide data via one channel but not allow redistribution via others.
- You must contact the corresponding authority for each jurisdiction. For US patents contact USPTO, not EPO or WIPO.
- EPO is the most impactful player in making global patent text accessible, providing data for multiple jurisdictions.
Understanding patent data categories
When working with patent data, there are four categories.
- bibliographic: Basic metadata like title, inventor names, applicant organizations, filing and publication dates, patent classifications (IPC, CPC, USPC, ...), as well as citation information, patent family relationships, and priority data that connects related applications across jurisdictions.
- legal events: Status changes like grant, lapse, withdrawal, and transfer of rights, plus procedural events including office actions, fee payments, deadlines, and oppositions that track the patent's journey through examination and maintenance.
- drawings: Technical illustrations and diagrams that visually represent the invention's components and embodiments.
- patent text: The core textual content of the patent document, including the detailed description and claims. While title and abstract are typically considered bibliographic metadata, they also appear as part of the full text document.
The evolution of patent text data
The first patents date back to 1449 in England. Today, databases like EPO's DOCDB (167 million documents as of 2025 week 47, dating back to 1782) give us a sense of the scale, though no single database contains all historical patents.

Let's think about the origin of this data. When someone wants to request protection for an invention, this involves writing and often drawing it. Early patents were handwritten, then typewritten. These patents have been digitized by scanning the original documents, resulting in image files such as TIFFs. These are not character-encoded (character-encoded text is also called full-text or machine-readable text), meaning you cannot search or select the text. To achieve this, often another digitization step is needed: OCR (Optical Character Recognition) that converts the image information into text. However, OCR works with probabilities, so the OCR-text sometimes does not exactly match the text in the image. For instance, paragraph numbers printed on the side of a document might be incorrectly interpreted as part of the claim text body, or entire paragraphs may come out as complete gibberish.

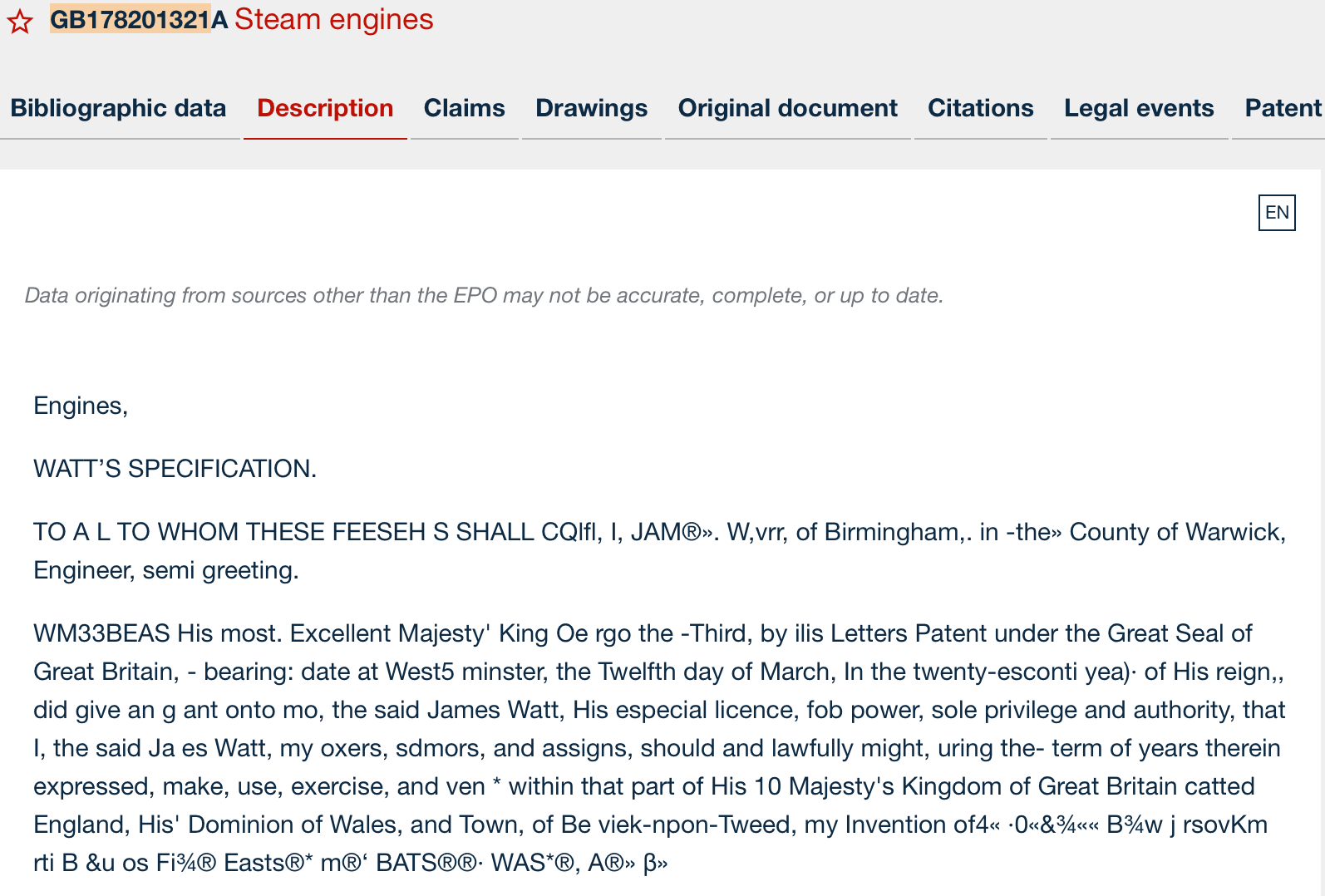
It's possible to integrate OCR-text into image-based PDFs, allowing you to select the text. To make it even more confusing, nowadays operating systems (computer and mobile) have integrated OCR capabilities, which allow you to select text directly from image-only files without any embedded character-encoded text.
The OCR-text is of course not only used for extending PDFs but also for building patent text databases. When exchanging this data programmatically (be it as single patent or as bulk data), XML is often used as the exchange format.
Nowadays patent documents are created digitally, so there's no need to OCR them. The text is character-encoded as it's created.
The decentralized reality of patent text bulk data access
Patents are national rights, managed by authorities that are responsible for certain jurisdictions. Each authority might handle this process differently. When you want to retrieve patent text bulk data from a certain jurisdiction, you usually need to obtain it from the corresponding authority. For US patent text, you contact the USPTO, not the DPMA, EPO, or WIPO.
However, some authorities do provide patent text data for associated jurisdictions. For example, EPO provides national full-text data for France, Spain, Switzerland, and the United Kingdom besides the EP patent text.
So, the bottom line is there's no central authority that delivers all patent texts.
Not all patent text is even digitized.
From some perspectives, old patents are less important than recent ones. Consider patents that are 30 years old and no longer active or in force, or patents from the 19th century where the described invention is no longer relevant.
Some jurisdictions therefore decide to OCR only more recent documents. Sometimes OCR was done years ago, and re-OCR would deliver better results, but authorities decide it's not worth the effort.
Due to the decentralized nature of this, the data formats (for example, how to express patent text as XML) differ between authorities. This makes it difficult not only to obtain patent text from various authorities but also to handle the different formats required to work with them.


The economics of patent text distribution
Speaking of effort, maintaining the archive and providing data on request costs money. Patent authorities therefore usually charge for delivering patent data, especially for bulk data or programmatic access via APIs.
Back in the day, for some jurisdictions, you had to pay a fee per document.
Due to digitization, it requires less effort to maintain and provide data, making it cheaper to obtain. EPO recently made some of their bulk data products free, for example EP full text.
When paying for patent texts from authorities, you enter into an agreement about how you're allowed to use them. Redistribution rights, for instance, are carefully controlled. So even though EPO may provide Chinese full text via Espacenet, they may not be allowed to redistribute this information via other channels, be it bulk data via BDDS or single documents via OPS.
OPS, for example, supports full text for the following authorities: EP, WO, AT, BE, BG, CA, CH, CY, CZ, DK, EE, ES, FR, GB, GR, HR, IE, IT, LT, LU, MC, MD, ME, NO, PL, PT, RO, RS, SE, and SK (as of this writing).
Espacenet, however, provides full text from more authorities. While OPS provides WO for single applications, if you're interested in WO bulk data, you need to reach out to WIPO.
Patent text aggregators and the future
Many providers have built custom patent databases containing patent texts from numerous authorities, including free options like Google Patents and EPO Espacenet, and paid services from Questel or Minesoft. They obtain historical data (sometimes referred to as back files) and recent deliveries and have an import process to load that data into a common format (ETL process). Based on that, they build indices to enable full text search or vector databases to run semantic search.
By far the most impactful player in making global patent text data accessible is EPO, not WIPO or any other authority or provider. It would be great to have a Wikipedia / Hugging Face of worldwide patent texts including API and bulk data access, a nonprofit service funded by the community. To realize this, it would be best to have national authorities generate and provide that data in a standardized format rather than offloading all the work to a single point. While this might seem like a naive vision, I'm confident it will become reality someday, whether driven by the EPO due to its political clout and financial resources, by a nonprofit organization due to its greater flexibility, or even by a cooperative. You might think of The Lens, but they didn't focus on broad full text support, and their sustainability model means it's not a free tool for most commercial use cases despite offering some free options.
If you or your organization are interested in contributing to or supporting such an initiative, I'd welcome a conversation: info@patent.dev
So why am I confident this will become reality? I've dealt with pallets of CDs and used AWS Snowball service to send patent data across the country by mail instead of via the internet. Back in those days, some would have claimed it was naive to think you could someday download gigabytes of free patent data within minutes on a regular basis. Yet that's now true for US and EPO bulk data products, not to mention services like Docker Hub or Hugging Face which handle enormous traffic loads without charging.